โลกแห่งการค้นหากำลังเผชิญกับการเปลี่ยนแปลงครั้งใหญ่ที่สุดในรอบทศวรรษ เรากำลังก้าวข้ามยุคที่การค้นหาจำกัดอยู่แค่ “ตัวอักษรในกล่องสี่เหลี่ยม” ไปสู่ยุคที่ “ทุกสิ่งที่คุณเห็นคือคำค้นหา”
ลองนึกภาพพฤติกรรมผู้บริโภคยุคใหม่ พวกเขาเห็นรองเท้าที่ชอบบน Instagram แต่ไม่รู้ยี่ห้อ แทนที่จะพยายามพิมพ์อธิบาย พวกเขาแคปหน้าจอแล้วใช้ Google Lens ค้นหา หรือพวกเขาอาจกำลังซ่อมซิงค์ล้างจานแล้วถ่ายวิดีโอสั้นๆ ถาม AI Assistant ว่า “เสียงกึกๆ แบบนี้เกิดจากอะไร และต้องหมุนวาล์วตัวไหน”
นี่คือยุคของ Visual Search และ Multimodal AI (AI ที่เข้าใจข้อมูลหลายรูปแบบพร้อมกัน ทั้งภาพ เสียง และข้อความ)
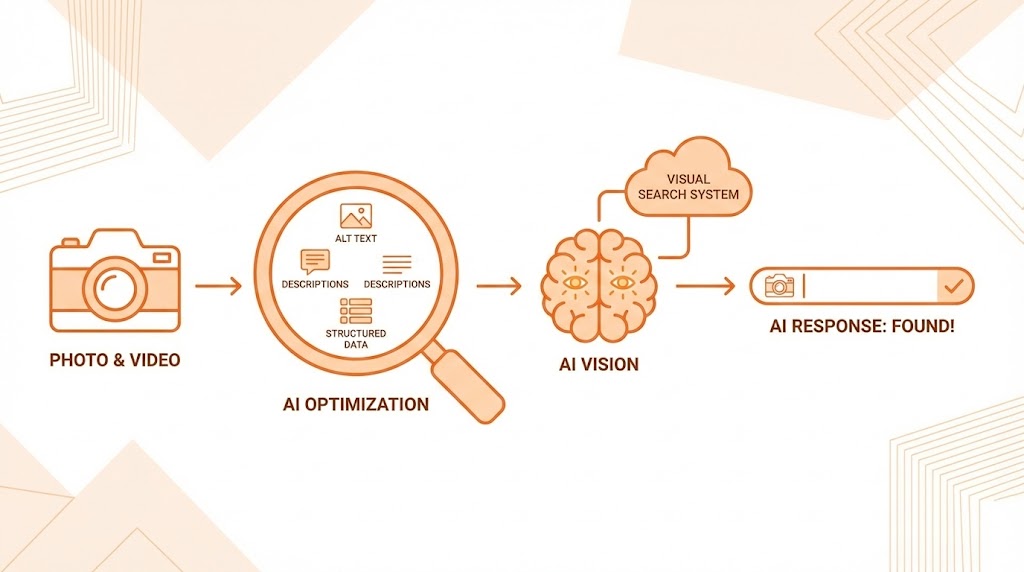
ปัญหาคือ AI ไม่ได้มีดวงตาเหมือนมนุษย์ มันไม่ได้ “ดู” รูปภาพแล้วเข้าใจทันทีว่า “อ๋อ นี่คือรองเท้าวิ่งสำหรับคนเท้าแบน สภาพดี ราคาคุ้มค่า” แต่ AI “ประมวลผลข้อมูล” ที่ซ่อนอยู่ในพิกเซลเหล่านั้น
หากรูปภาพและวิดีโอของคุณเป็นเพียงไฟล์ดิจิทัลที่ว่างเปล่า ไม่มีบริบท ไม่มีข้อมูลกำกับ สำหรับ AI แล้ว มันก็ไม่ต่างอะไรกับ “พื้นที่สีดำ” ที่ไม่มีความหมาย และแน่นอนว่า AI จะไม่มีวันหยิบสิ่งมองไม่เห็นไปนำเสนอเป็นคำตอบให้ผู้ใช้งาน
บทความนี้คือคู่มือเชิงลึกในการเปลี่ยนสินทรัพย์ดิจิทัลของคุณจาก “ภาพไร้วิญญาณ” ให้กลายเป็น “ข้อมูลภาพอัจฉริยะ” ที่พร้อมให้ AI รุ่นใหม่ๆ มองเห็น เข้าใจ และดึงไปเป็นคำตอบอันดับหนึ่งในโลก Visual Search
บทที่ 1: ทำความเข้าใจวิธีที่ AI “มองเห็น” โลก (The AI Vision Mechanism)

ก่อนจะไปสู่วิธีทำ เราต้องเข้าใจหลักการพื้นฐานก่อนว่า AI ยุค Generative Engine (เช่น Google SGE, ChatGPT Vision, Bing) ประมวลผลภาพอย่างไร
AI ไม่ได้พึ่งพาแค่อย่างใดอย่างหนึ่ง แต่ใช้การผสมผสานข้อมูล 3 ส่วนหลักเพื่อสร้าง “ความเข้าใจ”:
- Computer Vision (การมองเห็นของคอมพิวเตอร์): อัลกอริทึมจะสแกนพิกเซลในภาพเพื่อระบุวัตถุ (Object Recognition) เช่น แยกแยะว่าในภาพมี “คน”, “สุนัข”, “ภูเขา” หรืออ่านตัวหนังสือที่อยู่ในภาพ (OCR)
- Contextual Metadata (ข้อมูลบริบท): นี่คือสิ่งที่มนุษย์ต้องป้อนให้ AI เช่น ชื่อไฟล์, Alt Text, และที่สำคัญที่สุดคือ Structured Data (Schema Markup) ซึ่งเปรียบเสมือนล่ามแปลภาษาภาพให้เป็นภาษาเครื่อง
- Surrounding Content (เนื้อหาแวดล้อม): AI จะอ่านข้อความที่อยู่รอบๆ รูปภาพหรือวิดีโอนั้นๆ (เช่น ย่อหน้าก่อนหน้า, แคปชั่น, หัวข้อบทความ) เพื่อตีความว่าภาพนี้สื่อถึงอะไรในบริบทนั้นๆ
กฎเหล็ก: หาก Computer Vision ของ AI สงสัยว่าภาพนี้คือ “แอปเปิ้ล” แต่มันไม่มี Contextual Metadata ยืนยัน และเนื้อหาแวดล้อมพูดถึงเรื่อง “บริษัทเทคโนโลยี” AI ก็อาจไม่มั่นใจที่จะสรุปว่ามันคือ “ผลไม้” หน้าที่ของเราคือทำให้ข้อมูลทั้ง 3 ส่วนนี้สอดคล้องกันอย่างไร้ที่ติ
บทที่ 2: ยุทธวิธีปรับแต่ง “รูปภาพ” ให้ AI ตกหลุมรัก (Image Optimization for AI)
การทำ Image SEO แบบเดิมที่เน้นแค่ใส่คีย์เวิร์ดใน Alt Text นั้นไม่เพียงพออีกต่อไป ในยุค GEO (Generative Engine Optimization) เราต้องทำมากกว่านั้น:
1. คุณภาพและความชัดเจนคือหัวใจ (Clarity as King)
AI ชอบภาพที่ “เคลียร์” หากคุณขายกระเป๋า ภาพหลักควรมีกระเป๋าเป็นพระเอกที่โดดเด่น ชัดเจน แสงดี และไม่มีสิ่งรบกวนสายตา (Visual Clutter) มากเกินไป
- ทำไม: Computer Vision ทำงานได้แม่นยำที่สุดเมื่อวัตถุหลักแยกออกจากฉากหลังได้ง่าย หากภาพรก AI อาจจับโฟกัสผิดจุดและจัดหมวดหมู่ภาพของคุณผิด
- High-Resolution: ใช้ภาพความละเอียดสูง (แต่บีบอัดให้โหลดเร็วแบบ WebP) เพราะ AI สามารถซูมเข้าไปดูรายละเอียดเล็กๆ น้อยๆ เช่น พื้นผิววัสดุ หรือข้อความเล็กๆ บนฉลากสินค้าได้
2. สร้าง “บริบทอัจฉริยะ” ด้วย Structured Data (Visual Schema)
นี่คือเทคนิคที่ทรงพลังที่สุดและถูกมองข้ามมากที่สุด การใช้ Schema Markup คือการบอก AI ตรงๆ ว่าภาพนี้คืออะไร
- Product Schema: หากเป็นภาพสินค้า ต้อง ใส่ข้อมูล
imageลงใน Product Schema เสมอ และเชื่อมโยงกับข้อมูลอื่นๆ เช่นprice,availability, และreviewAI จะชอบมากเพราะสามารถดึงไปแสดงเป็น Rich Result ที่เป็นภาพพร้อมราคาได้ทันที - ImageObject Schema: สำหรับภาพประกอบบทความทั่วไป ใช้
ImageObjectเพื่อระบุรายละเอียด เช่น ใครเป็นผู้สร้างภาพ, ลิขสิทธิ์, และคำบรรยายภาพ (Caption) ที่เจาะจง
3. Alt Text และ Filename ยุคใหม่ (Descriptive over Keyword-Stuffed)
เลิกใช้ Alt Text แบบเก่าที่ยัดเยียดคีย์เวิร์ด เช่น alt="รองเท้า รองเท้าวิ่ง รองเท้าสีแดง ซื้อรองเท้า"
AI ยุคใหม่ต้องการคำอธิบายที่เป็นธรรมชาติและให้ข้อมูลเชิงลึกเกี่ยวกับสิ่งที่อยู่ในภาพจริงๆ (Descriptive Alt Text)
- ตัวอย่างที่ดี:
alt="รองเท้าวิ่งผู้ชายยี่ห้อ Nike รุ่น Pegasus 40 สีแดง กำลังถูกทดสอบวิ่งบนพื้นถนนเปียก แสดงให้เห็นการยึดเกาะ" - การเขียนแบบนี้ช่วยทั้งผู้พิการทางสายตา และช่วยให้ AI Models ที่มีความสามารถด้านภาษา (LLMs) เข้าใจบริบทของภาพได้ลึกซึ้งขึ้น
4. เนื้อหาแวดล้อมต้องสอดคล้อง (Contextual Relevance)
อย่าวางภาพไว้โดดๆ โดยไม่มีคำอธิบาย AI จะให้ค่าน้ำหนักกับข้อความที่อยู่ “ชิด” กับภาพมากที่สุด
- Caption (คำบรรยายใต้ภาพ): ควรเขียนสรุปใจความสำคัญของภาพนั้นๆ
- Adjacent Text: ย่อหน้าที่อยู่ก่อนและหลังรูปภาพ ควรมีเนื้อหาที่อธิบายขยายความสิ่งที่อยู่ในภาพ หากภาพคือกราฟแสดงสถิติ เนื้อหารอบข้างต้องอธิบายว่าสถิตินั้นหมายถึงอะไร
บทที่ 3: ยุทธวิธีปรับแต่ง “วิดีโอ” ให้ AI เข้าใจทุกเฟรม (Video Optimization for AI Awareness)
วิดีโอคือสื่อที่ AI ทำความเข้าใจได้ยากที่สุดในอดีต แต่ปัจจุบัน Multimodal AI สามารถ “ดู” และ “ฟัง” วิดีโอได้แล้ว หน้าที่ของเราคือช่วยให้มันจับใจความได้ง่ายขึ้น:
1. Transcript และ Closed Captions (CC) คือสิ่งที่ขาดไม่ได้
นี่คือกฎข้อแรกและสำคัญที่สุด AI ส่วนใหญ่ยังคง “อ่าน” วิดีโอผ่านข้อความ transcripts เป็นหลัก
- ต้องแม่นยำ: อย่าพึ่งพาระบบ Auto-generate ของแพลตฟอร์มเพียงอย่างเดียว เพราะมักมีคำผิด โดยเฉพาะคำเฉพาะทางหรือชื่อแบรนด์ คุณต้องตรวจสอบและแก้ไขไฟล์ .SRT ให้ถูกต้อง 100%
- ใส่ข้อมูลที่ไม่ใช่คำพูด: หากในวิดีโอมีเสียงสำคัญๆ เช่น [เสียงเครื่องยนต์สตาร์ทไม่ติด] หรือ [เสียงสัญญาณเตือนภัยดัง] ควรใส่ไว้ใน Captions ด้วย เพื่อให้ AI เข้าใจบริบทเสียง
2. Video Schema Markup และ Key Moments
บอก AI ว่าส่วนไหนของวิดีโอที่สำคัญที่สุด
- VideoObject Schema: ใส่ข้อมูลพื้นฐาน เช่น ชื่อคลิป, คำอธิบาย, ความยาว, และวันที่อัปโหลด
- Key Moments (Clip Schema): นี่คือทีเด็ด! คุณสามารถระบุ Timestamps ใน Schema เพื่อบอก Google ว่า “วินาทีที่ 0:45 เริ่มสอนวิธีเปลี่ยนแบตเตอรี่” และ “วินาทีที่ 2:15 สอนวิธีรีเซ็ตเครื่อง”
- ประโยชน์: เมื่อผู้ใช้ค้นหาคำถามเฉพาะเจาะจง เช่น “วิธีรีเซ็ตเครื่องรุ่น X” AI ของ Google สามารถดึงคลิปวิดีโอของคุณ และกระโดดไปยังวินาทีที่ 2:15 ให้ผู้ใช้ทันที นี่คือสุดยอดประสบการณ์ Visual Search ที่ AI ต้องการนำเสนอ
3. ปรับแต่ง Thumbnail ให้สื่อความหมาย
Thumbnail คือ “ปกหนังสือ” ของวิดีโอ มันคือสิ่งแรกที่ทั้งมนุษย์และ Computer Vision ของ AI มองเห็น
- ชัดเจนและตรงประเด็น: หากวิดีโอสอนทำอาหาร เมนูนั้นต้องดูน่ากินและชัดเจนบนปก
- ข้อความบนภาพ (Text Overlay): ใช้ข้อความสั้นๆ บน Thumbnail ที่สรุปหัวใจสำคัญของคลิป AI สามารถอ่านข้อความเหล่านี้ได้ (OCR) และใช้เป็นข้อมูลประกอบการตัดสินใจว่าวิดีโอนี้เกี่ยวกับอะไร
4. เนื้อหาภายในวิดีโอต้องชัดเจน (Visual Clarity in Motion)
หากคุณทำวิดีโอรีวิวสินค้า พยายามให้มีช็อตที่เห็นตัวสินค้าชัดเจน นิ่งๆ และแสงพอเพียง เพื่อให้ AI สามารถจับภาพ (Frame Grab) ไปวิเคราะห์ได้ง่าย หากกล้องสั่นไหวตลอดเวลา หรือมืดเกินไป AI อาจไม่สามารถระบุวัตถุในวิดีโอได้
บทสรุป: เปลี่ยน Visuals ให้เป็น Visual Assets
ในอนาคตอันใกล้ เมื่อผู้ใช้ถาม AI ว่า “อยากแต่งห้องสไตล์มินิมอล งบ 5,000 บาท ช่วยออกแบบและหาร้านซื้อของให้หน่อย”
AI จะไม่เพียงแค่ค้นหาบทความ แต่มันจะ:
- สแกน หารูปภาพห้องตัวอย่างสไตล์มินิมอลที่ตรงกับความต้องการ
- ระบุ เฟอร์นิเจอร์ชิ้นต่างๆ ในภาพนั้นด้วย Computer Vision
- ค้นหา ร้านค้าที่ขายสินค้านั้นๆ โดยอิงจาก Product Schema ที่เชื่อมโยงกับภาพ
- นำเสนอ ออกมาเป็นคำตอบที่สมบูรณ์แบบ ทั้งภาพแรงบันดาลใจและลิงก์สินค้า
หากรูปภาพและวิดีโอของคุณยังเป็นเพียงแค่ “ไฟล์ภาพ” ธรรมดาๆ ที่ไม่มีข้อมูลกำกับ คุณจะไม่มีวันได้เป็นส่วนหนึ่งของคำตอบนี้
การปรับแต่ง Visual Content ให้ AI “มองเห็น” จึงไม่ใช่ทางเลือกเสริมอีกต่อไป แต่มันคือ ยุทธศาสตร์ความอยู่รอด ในยุคที่การค้นหาด้วยภาพและการตอบคำถามด้วย AI กำลังกลายเป็นมาตรฐานใหม่ของการออนไลน์ เริ่มต้นเปลี่ยนสินทรัพย์ดิจิทัลของคุณให้มี “ดวงตา” และ “สมอง” ตั้งแต่วันนี้ เพื่อให้แน่ใจว่าเมื่อลูกค้า (หรือ AI ของพวกเขา) มองหา… พวกเขาจะมองเห็นคุณ